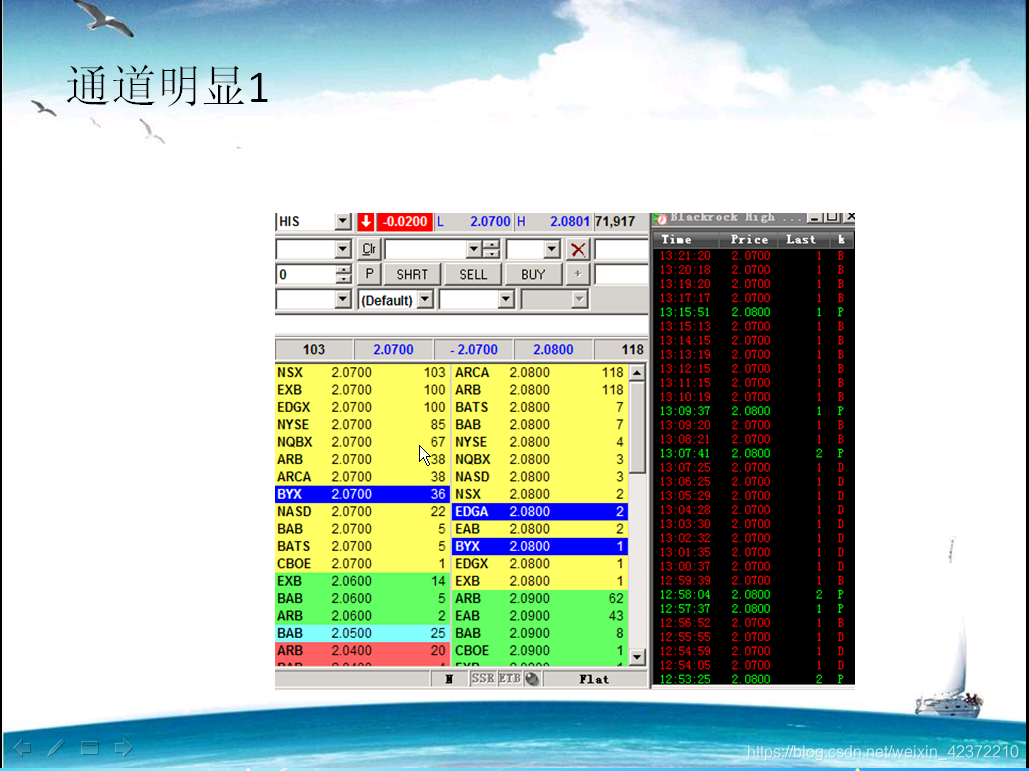
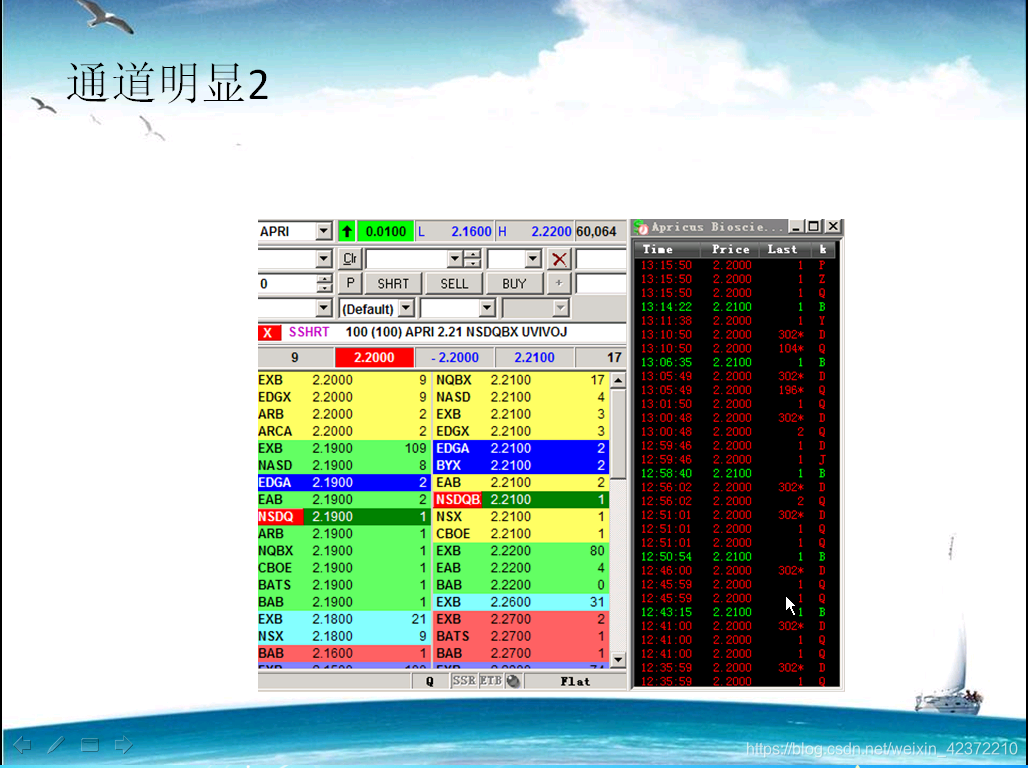
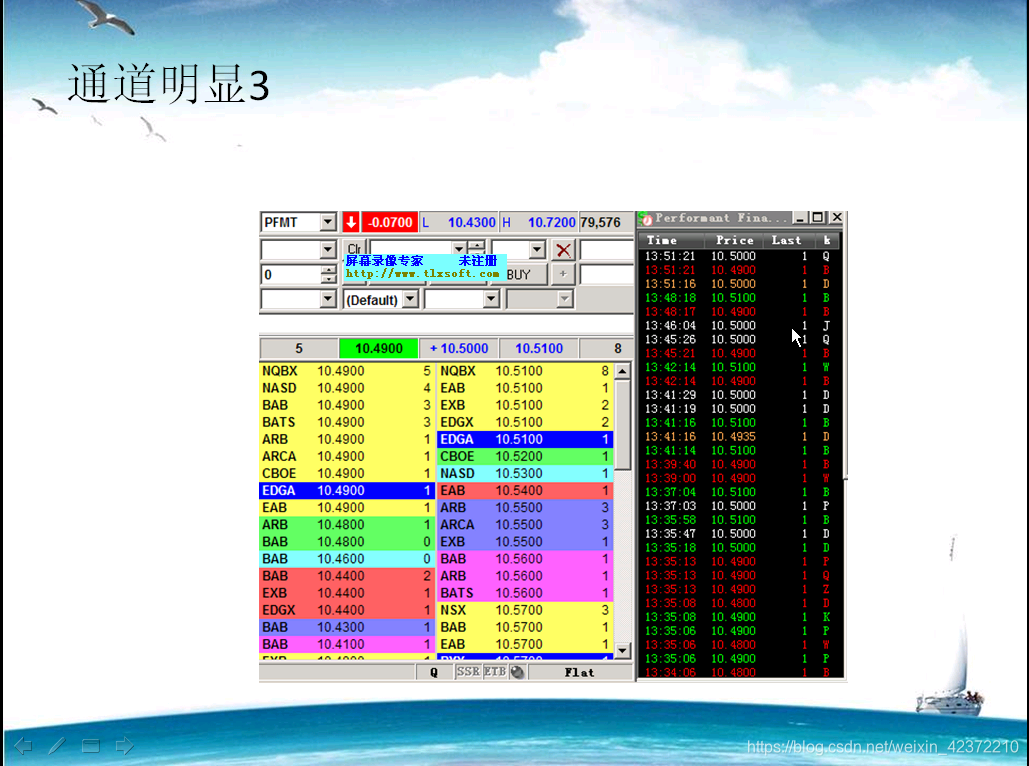
黑盘第一课
黑盘投票网站
因为这个网站需要一页一页的粘贴复制名字,所以我想用我的Python知识来解析网页,然后写入到txt文件中
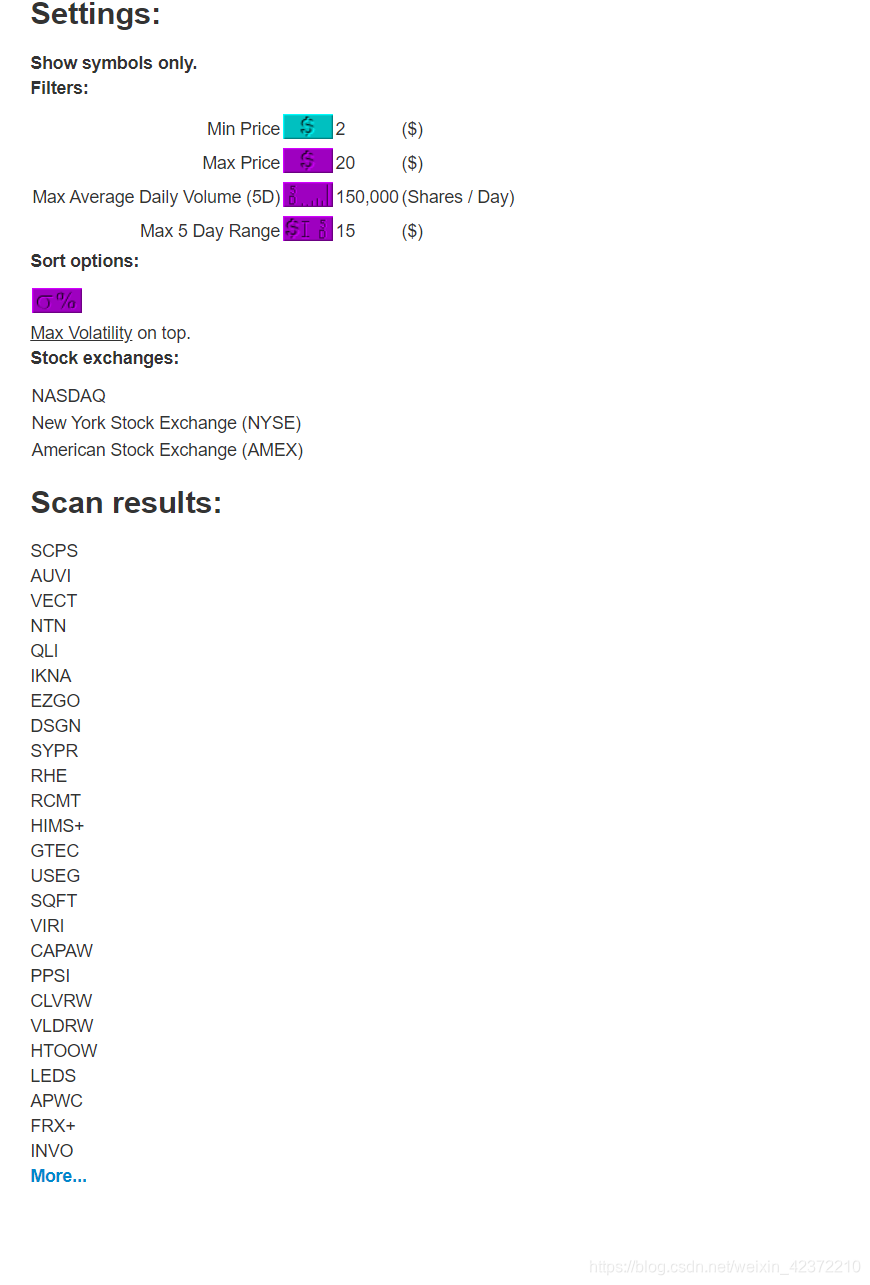
程序功能
我的投票标准是根据培训中老师制定的标准来的。 本网站不提供下载功能。 也有可能我找不到。 我只能一页一页地粘贴和复制。 现在,我想用python来帮助我下载数据。 坠落。
想法分析
首先,构造网址:
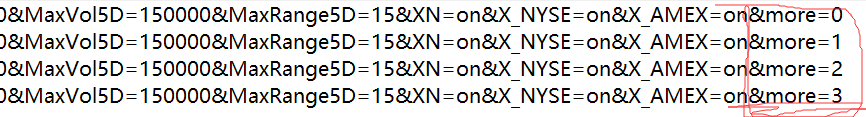
经过测试,发现每个网页地址中最后一个参数&more就是翻页功能。 我们还发现你的投票标准实际上是参数。 这是一个比较简单的网站,没有反扒机制。
接下来我将使用python来解析网页的地址
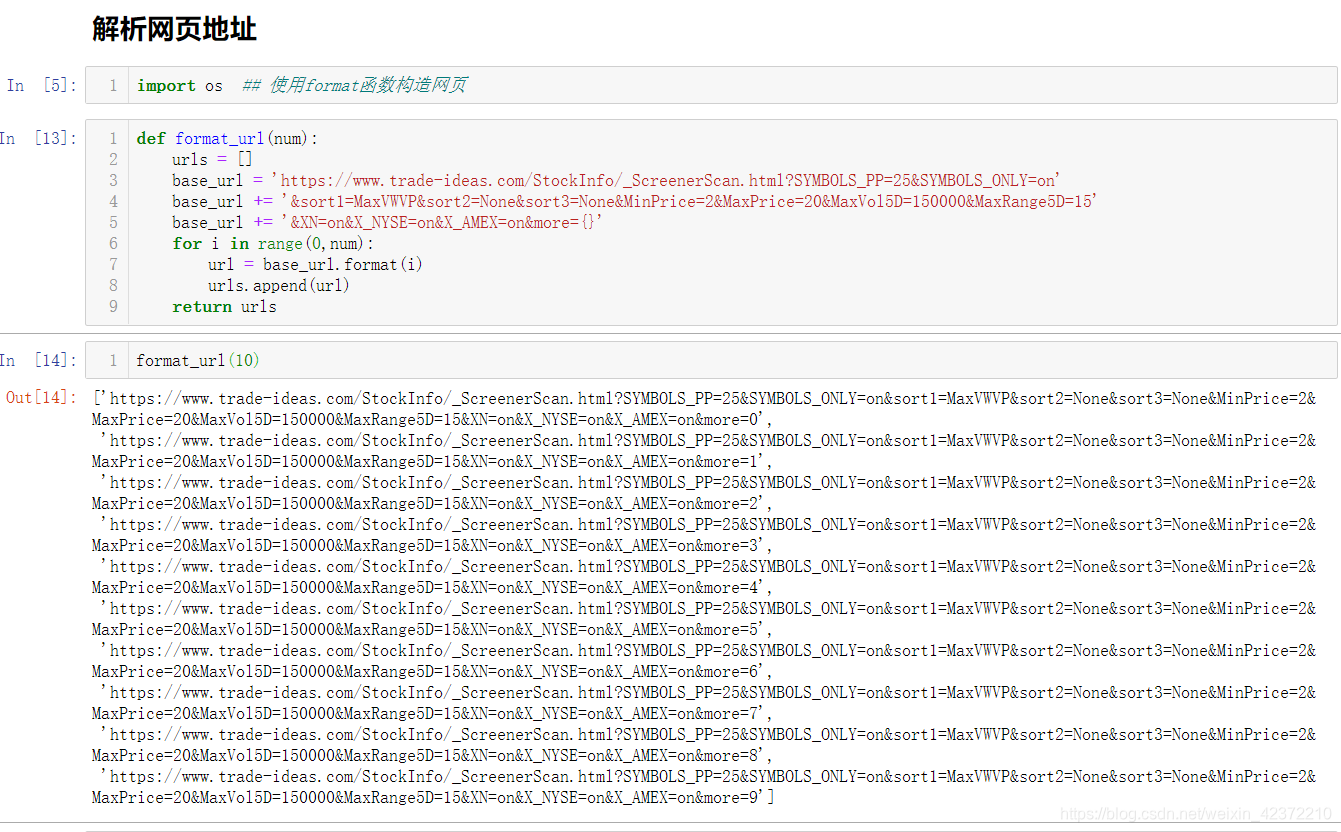
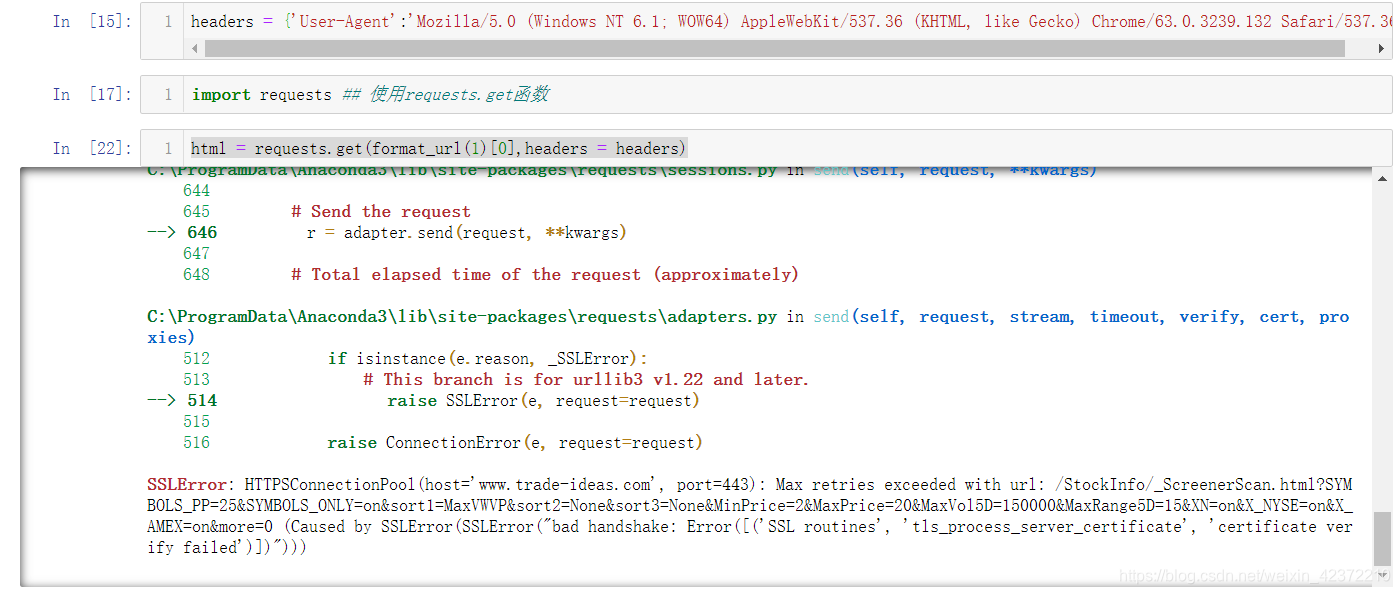
解析网页时出现此错误。 该错误是因为网页证书已过期。 具体解决方案我参考了以下网址:
参考
本来想用json包中的loads函数等待的网页源码来组织一下,但是后来发现了如下错误:
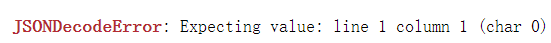
在百度上搜了一个小时也没能解决这个问题,然后我想到了用通配符来解决这个问题,匹配我要爬取的股票名称。
参考
获得了以下结果:
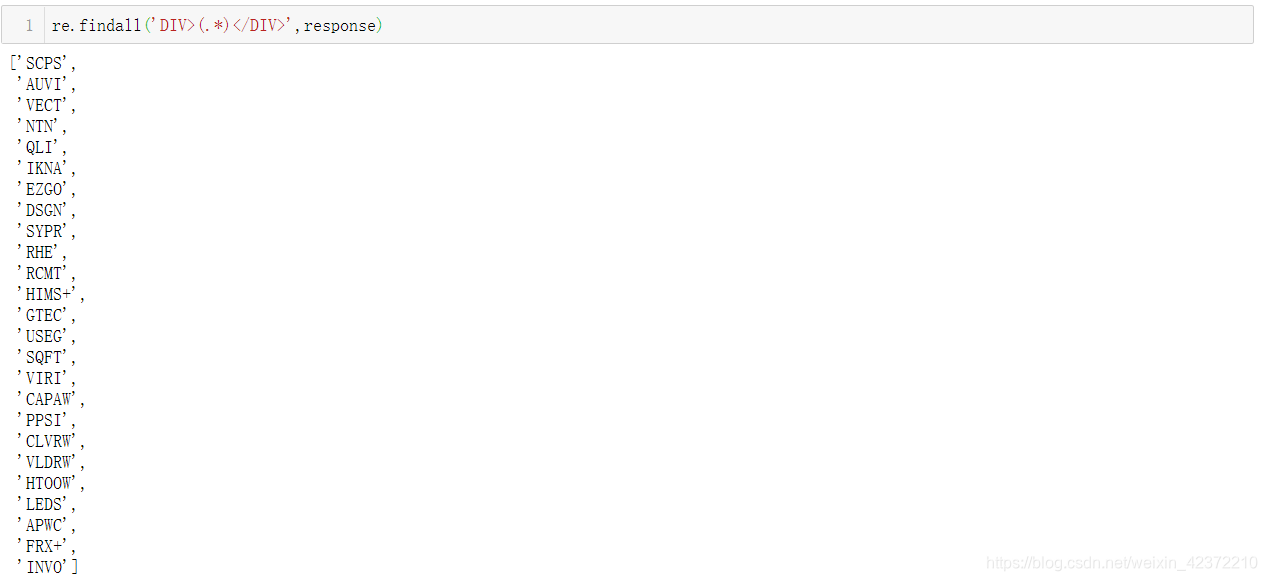
上述任务仍然需要将获得的列表写入文本文件的功能。

参考
最后还有一个问题没有解决,就是不知道这个网页有多少页,最后一页在哪里?
我用if来判断读取列表是否为空。 如果它是空的,我结束 while 循环。

今天的编程很简单很基础,但是花了我两个半小时。 我以为我能在15分钟内写完的东西实际上花了我两个半小时才写完。 原来我的编程基础太差了。 每当我出错的时候,我就查百度,花了我很长时间才明白,然后我又花了一段时间自己测试。 以后有时间的话,我会研究一下常用包的帮助文档,了解一下里面的功能,这样下次写的时候就不会那么迷茫了。 花了很大的力气。 我需要学习的东西有很多。 以前以为爬到网页上的数据就很乐意了,现在发现都是基础的东西,基础的代码。
我需要重新研究通配符包,我认为它非常有用。
蟒蛇代码
import os ## 使用format函数构造网页
import requests ## 使用requests.get函数
import re
def format_url(num):
base_url = 'https://www.trade-ideas.com/StockInfo/_ScreenerScan.html?SYMBOLS_PP=25&SYMBOLS_ONLY=on'
base_url += '&sort1=MaxVWVP&sort2=None&sort3=None&MinPrice=2&MaxPrice=20&MaxVol5D=150000&MaxRange5D=15'
base_url += '&XN=on&X_NYSE=on&X_AMEX=on&more={}'
url = base_url.format(num)
return url
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
result=[];
i=0
while(1):
response = requests.get(format_url(i),headers = headers,verify=False).text
res = re.findall('DIV>(.*)